Technology
How Zero Trust Security Protects VPS Hosting
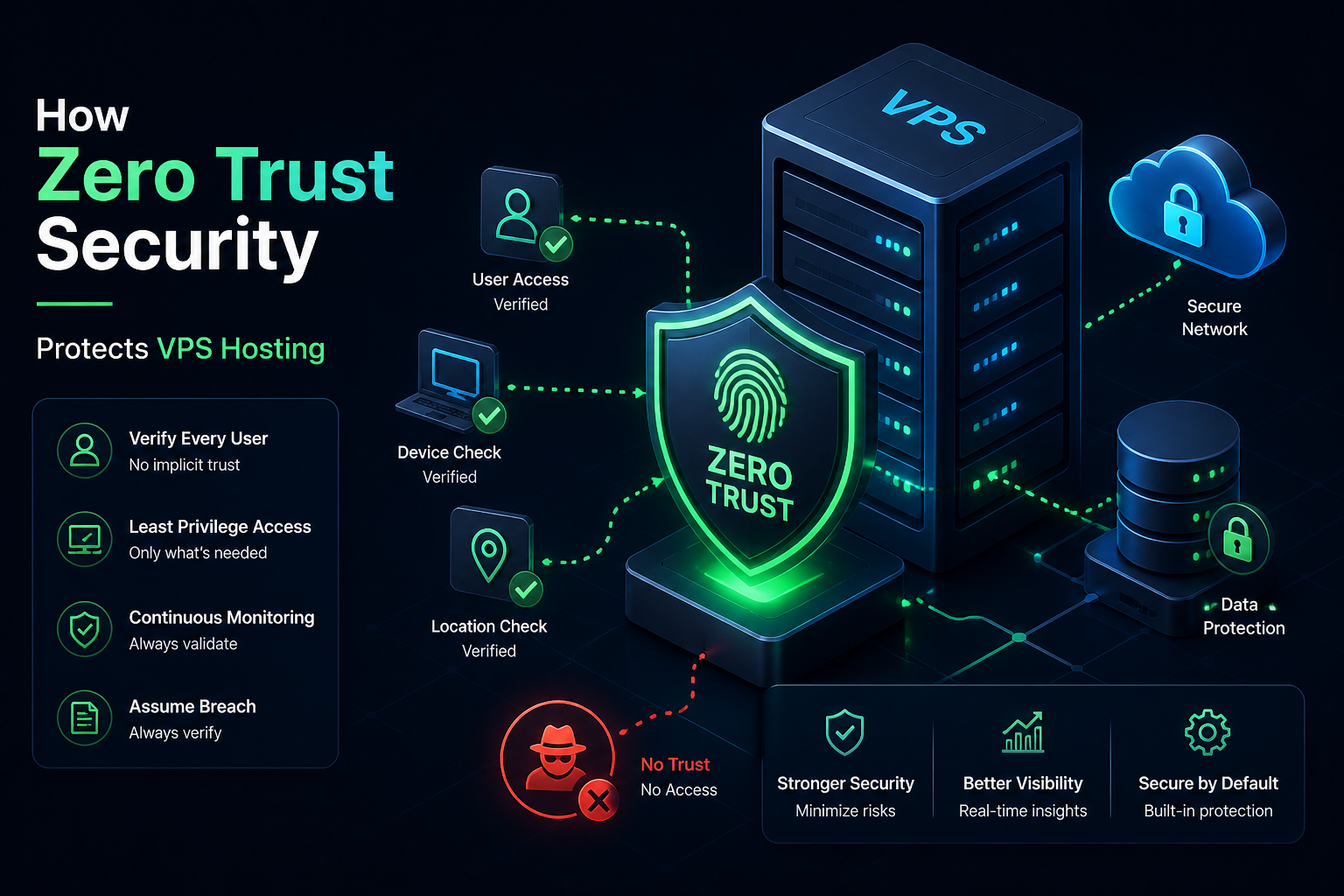
Virtual private servers sit in an exposed position by design. Unlike an office workstation tucked behind a corporate firewall, a VPS has a public IP address, accepts connections from anywhere in the world, and runs continuously — often without a human watching over it. That combination makes it a high-value target. Traditional security models built on perimeter defense — the idea that anything inside the network can be trusted — are no longer adequate for this threat landscape. Zero Trust is the framework that replaces that assumption entirely, and in 2026, it has become the most important shift in how VPS hosting is secured.
What Zero Trust Actually Means
Zero Trust is not a product you buy or a single tool you install. It is a security philosophy built around one core principle: never trust, always verify.
While traditional security models relied on a “castle-and-moat” approach — where the network perimeter is trusted, and access is granted based on location — Zero Trust focuses on verifying identities and device compliance regardless of location. It mandates strict identity verification and authorization for every access request, enforcing security policies based on the principle of least privilege.
Applied to VPS hosting, this means that no user, application, or service is granted access simply because it is on the same network or has connected before. Every request is treated as potentially hostile until it is verified. Continuous verification means you never inherently trust any user, device, or application, regardless of its location — inside or outside the network perimeter.
This shift matters because the old model assumed that threats come from outside. The reality is very different. Compromised credentials, malicious insiders, vulnerable applications running on the same server, and lateral movement from one breached service to another are all threats that originate from within a network. Zero Trust eliminates the blind trust that makes those attacks so damaging.
Why VPS Hosting Specifically Needs Zero Trust
A VPS is, by nature, internet-facing infrastructure. Because a VPS is highly customizable and directly exposed to the internet, it is the user’s responsibility to manage the operating system, applications, and security layers. Applying Zero Trust principles is the most effective way to manage the inherent risk of public-facing infrastructure.
The traditional approach to securing a VPS involved setting up a firewall, locking down SSH access, and keeping software updated. Those measures are still necessary, but they are no longer sufficient on their own. Modern VPS protection requires a systematic approach: from architecture to CI/CD. Standard measures like a firewall and regular updates are the baseline — but they are no longer enough.
Consider what happens when an attacker obtains valid credentials for your VPS through phishing, a data breach, or a brute-force attack. Under a traditional security model, those credentials are a skeleton key — the attacker is now “inside” and can move freely. Under Zero Trust, valid credentials alone are not enough. The request must also come from a verified device, pass behavioral checks, and be authorized for the specific resource being accessed, at that specific time.
The Core Pillars of Zero Trust for VPS Hosting
1. Identity Verification and Strong Authentication
The first line of Zero Trust defense is confirming that a user is who they claim to be — every single time they connect, not just at initial login. This means moving beyond static SSH keys and passwords toward multi-factor authentication for all administrative access.
Continuous authentication ensures that user sessions remain verified based on real-time risk assessments and not on one-time password checks. For VPS access, this translates to short-lived credentials, session tokens that expire after use, and MFA requirements that cannot be bypassed even for privileged accounts. Tools like Teleport and Cloudflare Access implement this by issuing short-lived SSH certificates rather than persistent keys — traditional SSH access relies on long-lived keys, jump hosts, and complex firewall rules, while modern zero-trust solutions eliminate these pain points by implementing identity-based access controls, short-lived certificates, and encrypted peer-to-peer connections.
2. Least-Privilege Access
Every user, application, and service running on or connecting to your VPS should have the minimum level of access needed to perform its specific function — and nothing more. This limits the blast radius of any single compromised account or process.
The default root user is all-powerful and therefore a great target. One of the most significant principles in VPS security is to reduce root usage: create a non-root user account with standard privileges immediately after initial setup, and reserve root access for operations that genuinely require it.
At the application level, this means database users who can only query the tables they need, API keys scoped to specific endpoints, and file system permissions that prevent web server processes from reading sensitive configuration files. Least-privilege access does not stop every attack, but it ensures that a breach of one component cannot immediately cascade into a full server takeover.
3. Micro-Segmentation
Micro-segmentation is one of Zero Trust’s most powerful defenses against lateral movement — the tactic attackers use to spread from one compromised service to others on the same server or network.
Micro-segmentation divides networks into small, isolated segments, each enforcing its own access controls, making it harder for attackers to pivot within the infrastructure. On a VPS running multiple services — a web application, a database, a mail server, a monitoring agent — micro-segmentation means each service communicates only with the specific other services it needs to, over defined ports and protocols. An attacker who compromises the web application cannot automatically reach the database or the mail server.
The philosophy of Zero Trust networking for VPS involves implementing micro-segmentation, applying internal firewalls to restrict traffic between your own services, and preventing an attacker from moving laterally in the event they have compromised one service. This can be implemented using iptables rules on Linux, Docker network policies, or dedicated firewall configurations that segment internal traffic just as aggressively as external traffic.
4. Continuous Monitoring and Anomaly Detection
Zero Trust does not assume that a verified session remains trustworthy for its entire duration. The security posture of users and devices is continuously monitored for anomalies and potential threats. Sensitive resources are isolated into smaller, protected segments to limit the spread of a potential breach.
For VPS hosting, continuous monitoring means watching for unusual patterns: a login from an unfamiliar geographic location, a user account suddenly accessing files it has never touched before, an outbound connection to an unknown IP, or a process consuming unexpected CPU resources. Tools like Fail2Ban, OSSEC, and auditd provide this visibility at the server level. Modern VPS protection using a Zero Trust stack incorporates AI-driven intrusion detection and prevention systems that can detect anomalies in real time, isolate processes, and even automatically restore configuration after an attack.
The goal is to reduce dwell time — the period between when an attacker gains access and when they are detected. The average dwell time in breaches without continuous monitoring is measured in weeks. With Zero Trust monitoring in place, anomalies are surfaced within minutes or hours.
5. End-to-End Encryption
Zero Trust assumes that any network, including your own internal network, could be compromised. Therefore, all traffic — not just traffic crossing the public internet — must be encrypted.
Zero Trust solutions mandate end-to-end encryption for all connections, both at rest and in transit. This ensures that sensitive data remains protected from eavesdropping or interception, even on unsecured networks. Encryption standards such as TLS and IPsec are enforced across all channels, with regular updates to protocols and keys to address evolving threats.
For a VPS environment, this means enforcing HTTPS for all web traffic, encrypting database connections even when the database is on the same server, encrypting data at rest on disk, and using encrypted tunnels like WireGuard for administrative access. WireGuard, together with SASE providers such as Tailscale or Cloudflare One solves several tasks at once: access to the server is strictly controlled, all traffic is encrypted, and geography does not matter — whether it is an office in one country or a remote worker in another.
6. Just-in-Time Access and Minimal Exposure
One of the most effective Zero Trust tactics for VPS security is making your server invisible by default. Rather than leaving SSH open on port 22 permanently — waiting for brute-force attempts — you only expose access when it is actively needed.
Applications and workloads are not reachable by default and only become accessible after strict validation. Techniques like just-in-time access and one-time, ephemeral connectivity further restrict potential attack vectors. Services like Cloudflare Access and Teleport implement this natively. Without them, you can approximate it by closing all administrative ports in your firewall by default and opening them only via an authenticated knock sequence or a VPN connection.
Port scanners are constantly sweeping the internet looking for exposed SSH, RDP, and admin panel ports. A server that does not expose these ports by default simply does not appear in those scans.
Implementing Zero Trust on Your VPS: Practical Starting Points
You do not need an enterprise security budget to begin applying Zero Trust principles to your VPS. Here is a practical sequence to follow:
- Start with authentication. Disable password-based SSH login and switch to key-based authentication. Add MFA for any control panel or admin interface. Consider deploying Tailscale or Cloudflare Access to gate SSH access behind identity verification.
- Apply least privilege immediately. Create non-root users for all services. Audit every running process and ask whether it needs its current level of access. Revoke anything that doesn’t.
- Segment your services. Use your firewall to block inter-service traffic that does not need to happen. Your web server should not be able to initiate connections to your database on its own — only respond to requests from your application layer.
- Enable logging and monitoring. Deploy auditd, Fail2Ban, or an equivalent to watch for suspicious activity. Set up alerting so that anomalies reach you in real time rather than sitting in a log file you check monthly.
- Encrypt everything. Enable full-disk encryption on your VPS storage, enforce TLS on all services, and audit your server for any service transmitting data in plaintext.
The Bottom Line
For a VPS that is constantly exposed to the internet, regular auditing transforms passive security into an active defense strategy. Instead of waiting for a breach, Zero Trust proactively identifies misconfigurations, outdated software, and excessive permissions before they become vulnerabilities.
The old perimeter defense model assumed the threat was outside. Zero Trust acknowledges that the threat can already be inside — through a stolen credential, a vulnerable plugin, a misconfigured service, or a compromised dependency. By verifying every request, restricting every permission, segmenting every service, encrypting every connection, and monitoring every session, Zero Trust turns your VPS from a single point of failure into a layered system where compromising one component does not hand an attacker the entire server. That shift in assumption is what makes it the defining security framework for VPS hosting in 2026.

A healthcare network can employ world-class clinicians and deploy state-of-the-art diagnostic imaging suites, but those assets remain entirely useless if a patient cannot physically reach the point of care. While emergency services handle high-acuity trauma transit, a much larger, quieter logistical gap exists for chronic, elderly, and mobility-impaired populations.
Non-Emergency Medical Transportation (NEMT) has transitioned from a minor administrative convenience into a mission-critical component of modern healthcare delivery. As health systems shift toward value-based care models, optimizing the patient transit layer is no longer optional; it is a financial and operational imperative.
Missed Appointments and Revenue Leaks
For specialized clinical environments and outpatient facilities, patient no-shows are a persistent drain on operational revenue. A single missed appointment leaves expensive equipment idle, disrupts physician scheduling patterns, and artificially inflates patient waitlists.
Statistics indicate that transportation barriers prevent millions of individuals from accessing necessary medical care annually. When chronic patients (requiring routine dialysis, oncological radiation, or post-surgical wound care) miss appointments due to a lack of reliable transit, their underlying conditions inevitably destabilize.
This creates a highly predictable, high-cost cycle: preventable medical non-compliance leads directly to an emergency department admission. By establishing structured, reliable NEMT corridors, healthcare organizations replace these costly acute-care surges with predictable, managed outpatient visits. This stabilizes internal workflows and protects consistent revenue streams across multi-site health systems.
Driving Down Hospital Readmission Rates
Under the Hospital Readmissions Reduction Program (HRRP), hospitals face financial penalties if specific patient populations are readmitted within a 30-day window following discharge. A primary catalyst behind these avoidable readmissions is the total breakdown of post-discharge care plans. They are frequently caused by a lack of transit options to pick up prescriptions or attend follow-up clinical audits.
Integrating a dedicated NEMT logistics framework directly into the inpatient discharge workflow ensures a seamless handoff from the bedside to the home environment. When a patient leaves the facility with their immediate post-acute transit pre-arranged, compliance rates climb sharply. Ensuring that a vulnerable patient actually arrives at their 48-hour follow-up appointment is the single most effective factor. A case management team can use it to clear bed capacity and safeguard hospital resource margins.
The Complexities of Modern NEMT Dispatching
On paper, arranging a non-emergency ride sounds like a basic taxi dispatch task. In practice, medical transportation logistics involve an intricate, high-stakes matrix of clinical compliance, passenger constraints, and varying fleet capabilities.
- Divergent Vehicle Acuity Requirements: A single shift may require a mix of standard ambulatory sedans, wheelchair-accessible vehicles (WAVs) with specialized hydraulic lifts, and non-emergency gurney vans equipped with specialized monitoring tools.
- Complex Multi-Payer Authorization Environments: Managing rides funded via state Medicaid programs, private managed care organizations (MCOs), or billing codes, and strict verification windows.
- Dynamic Patient Scheduling Realities: Unlike standard delivery logistics, medical transits are highly volatile. A clinical procedure that runs thirty minutes long or a delayed physician sign-off instantly de-synchronizes a driver’s subsequent pickup schedule.
To resolve these daily operational friction points, healthcare networks are moving away from legacy manual booking methods and fragmented spreadsheet trackers. Institutes are actively investing in custom healthcare software development to build specialized NEMT dispatch platforms. Such platforms automate vehicle assignment, optimize routing based on live traffic, and integrate directly with electronic health records (EHR).
Smart Software Integration Changes Patient Logistics
Resolving systemic transportation bottlenecks requires more than just adding more vehicles to a fleet or hiring more drivers. True efficiency stems from intelligent coordination and data visibility. Modern Non-Emergency Medical Transportation depends entirely on custom software solutions that bridge the information gap between clinics, drivers, and patients.
- Dynamic Geolocation and Auto-Routing: Specialized software engines analyze real-time vehicle locations and historical traffic patterns to assign incoming ride requests instantly, removing manual guesswork from dispatch desks.
- End-to-End Fleet Visibility: Real-time tracking modules give floor nurses and case managers precise arrival updates, completely eliminating the need for continuous follow-up phone calls to check a vehicle’s status.
- Automated EHR Trigger Arrays: Modern software integration allows a trip request to be automatically generated. The moment a doctor inputs a discharge order or schedules a recurring outpatient therapy inside the patient’s record, the workflows initiate.
- Consolidated Multi-Vendor Orchestration: Instead of relying on a single transport source, integrated networks connect internal fleets and third-party NEMT vendors. It transforms into a single operational interface, scaling capacity dynamically based on daily demand surges.
Conclusion
Patient transportation is no longer a peripheral logistical task to be outsourced and ignored. It is an active operational vector that dictates a health system’s bed turnover efficiency, readmission vulnerability, and overall clinical experience.
Hospitals that continue to manage their patient care tracks through unoptimized, manual legacy processes will continue to see their operational margins eroded. By employing data-driven Non-Emergency Medical Transportation platforms, healthcare providers resolve the challenges and escalate essential medical care.
Building these high-performance networks requires an engineering partner capable of designing secure, compliant software environments tailored to complex workflows. At Unique Software Development, we engineer custom enterprise applications built to meet the rigorous scale, security, and integration demands of modern healthcare infrastructure.

The message had been clear until recently: specialize. Choose a narrow field and dive into it, making yourself the world’s foremost expert in that particular thing. This is what I did, and for many years this path served me well. However, lately I have witnessed this approach being challenged, and I now believe that the highly competent generalist, who had been considered merely a jack of all trades and master of none for a long time, will be one of the most sought-after professionals in the near future.
The case for specialization is weakening
In an environment where specialized knowledge is rare and difficult to acquire, it was natural for the premium to be on specialization. If you were the person who had mastered something to a great degree, the very fact that there were so few people who possessed such knowledge created value for it. But the access to such specialized knowledge has become tremendously wide, and the competitive advantage held by the pure specialist is now narrowing. The fact that a competent generalist can access specialized knowledge easily means that the value of specialization is becoming less important.
It certainly doesn’t mean that expertise isn’t valuable, just that the pendulum has swung to the other side. It’s the generalists who can flow between different realms, recognize connections that experts fail to see, and build up an array of skills across disciplines who will create most of the value in the future. They don’t do anything better than the experts do – they’re just better at integrating all those little somethings into one big something.
The integration advantage
The actual power of the generalist lies in his integration, meaning his capability of taking something from other disciplines and combining them together into something which could not have been achieved by each of them independently. The majority of all innovations come precisely when a technique borrowed from one domain starts solving a problem in another domain, and it is the generalist, familiar with many domains, that sees this potentiality. The specialist, working on his own domain, fails to notice this technique just next to him.
Today’s technology magnifies the generalist by enabling one talented individual to piece together processes from several disciplines that previously would have taken a group of specialists to complete. A new generalist can lean on a broad FaddyAI tools stack to cover a range of functions competently, freeing them to focus on the integration and judgment that no tool provides.
Tools as a force multiplier
The specific reason why the generalist is now on the rise is because tools have made it much more feasible. In the past, being a generalist would mean being mediocre in all those areas because the idea was that if you tried to cover more ground, you wouldn’t have the expertise to perform well in any single area, which was the traditional complaint against generalists. However, if you use adequate tools for each area, the generalist’s responsibility becomes one of orchestration, not performance.
Herein lies the reversal of a time-tested principle. It is no longer necessary for the generalist to sacrifice either breadth or competence since the technology provides the competence within each field, whereas the generalist himself/herself contributes the expertise in combining various areas of knowledge. What emerges is a whole new breed of professionals that could not be imagined just a few years back; professionals that are competent precisely because they are generalists.
Developing as a generalist
If so, then your trajectory will be quite distinct from that of the specialist. While you may continue to delve ever more deeply into one area after another, what is even more important is that you learn how to build up expertise in multiple areas and, most importantly, how to learn rapidly, synthesize, and coordinate. It is this kind of coordination that makes breadth valuable, not breadth for its own sake. It is certainly not about knowing everything, because there is too much to know.
A balanced view
Nothing of this implies that specialization is not important anymore; there will always be a need for specialized individuals. What it means is that a capable generalist is not the underdog anymore. Building a personal stack around flexible options like an explore these AI tools approach is one practical way to develop the breadth that makes a modern generalist effective.
The well-rounded individual, dismissed for so long as someone who mastered nothing, is undergoing something of a quiet renaissance, and this is due to structure, not fashion. As specialized knowledge and skills become easily available, and as machines do the work of implementation, the range of integration of the generalist is now a real strength and no longer a weakness. It seems that the future will not belong to those at the extreme ends of specialization or generalization but to those in between who have the capacity for integration, a uniquely human talent.
What makes me finally believe the rise of the generalist is what I observe from the best performers I have met in real life. They might not be the deepest specialist around, but it is the rare one who sees the big picture, who can integrate the specialist knowledge into a cohesive whole. This integration becomes the increasingly rare talent, because while tools and specialists can provide you with deep knowledge on demand, wide understanding and judgment cannot come to you in the same way. The future is not about specialists becoming irrelevant, but about competent generalists, who can use a variety of tools and apply their skills across multiple disciplines, getting their due as true professionals instead of being labeled as jack-of-all-trades who could never really master one.

Every founder remembers the night before a launch when the build passes every test on the checklist and still finds a way to crash on a real phone. California-based app developers live with that feeling on a loop.
The market here does not wait. Investors want weekly updates, users uninstall after one bad crash, and competitors ship features faster than most teams can write a proper test plan.
That pressure is exactly why testing automation powered by AI has stopped being a nice idea and started being the thing keeping release schedules from falling apart.
When Weekly Releases Met A QA Team That Could Not Keep Up
Ten years ago, a mobile team might ship a meaningful update once a month and budget two or three days of dedicated QA before each release. That timeline does not exist anymore, not for teams trying to stay funded or stay ahead of three competitors building the same feature.
Weekly releases are the norm now, and plenty of teams push smaller updates daily on top of that. Manual regression testing just can’t keep up across the pile of devices and OS combinations a real app has to support.
And the fragmentation alone is enough to break a small QA team. iOS at least ships on a schedule you can plan around. Android doesn’t work that way. It’s spread across dozens of manufacturers and OS versions that never really retire, so something that runs perfectly on one phone can quietly fall apart on another two models down the line.
By the fifth time a tester clicks through the same flow that week, they’re not really seeing it anymore. That’s just how attention works. Burnout creeps in, and burned-out testers miss things, not because they’re careless, but because nobody can stay sharp doing the same click path two hundred times.
Gartner’s numbers back this up, too, and they’re worth sitting with for a second. The most recent Magic Quadrant on AI augmented testing tools says that by 2028, seventy percent of enterprises will have these tools wired into their engineering toolchain.
Compare that to just twenty percent in early 2025, and you’re looking at a jump most technologies never pull off in three years.
That kind of curve does not happen because a slide deck made AI testing sound exciting. It happens because teams drowning in release deadlines tried it, and it actually bought them time back.
For California teams specifically, the pressure compounds. Investors expect visible progress between funding rounds, and a bug that slips through during a demo week does more damage than the same bug would do in a slower-moving market.
Testing automation built around AI did not solve every problem here, but it solved the one that was costing the most time.
What Changes When Tests Can Adjust Themselves
The shift isn’t about replacing test scripts with some kind of magic fix. Think of it as giving those scripts room to bend when the app changes underneath them.
Take self-healing tests. A button moves, a label gets reworded, and instead of the test just failing and sitting there until someone notices, it adjusts the locator on its own. Machine learning handles the triage part too.
It looks at what changed in the code and figures out which tests even need to run, so you’re not waiting on the entire suite every time someone tweaks a button color.
Then there’s visual regression, which is honestly the one that saves the most arguments. It catches the pixel-level stuff nobody’s eyes are sharp enough to spot after staring at the same screen for six hours straight.
Most software and app development agencies are already folding pieces of this into delivery, even when a client never sees the word AI written into a statement of work.
An agency like 8ration, which builds apps for founders outside California as well as inside it, already runs AI-generated test cases against every build before a client sees a demo.
Yuri Kan, a senior QA lead who writes regularly about test automation, said something that stuck with me when he talked about where the real value goes from here.
It won’t be the engineers cranking out the most test scripts who matter most. It’ll be the ones who can tell the AI what to test, then catch it when it’s wrong, which he says is a fundamentally different skill than scripting ever was.
Where AI Testing Actually Earns Its Keep
All of this sounds fine in theory, but it only matters if it shows up somewhere real, not in a roadmap slide promising fewer bugs next quarter. The actual test is whether it holds up across an ordinary week of shipping updates without everyone losing a weekend to it. Three places make that difference obvious fast.
Before a demo or a funding update
Speed is basically the whole game here. A consumer app can go from private beta to live on the App Store in six weeks flat, and a B2B tool might need to demo a brand new integration before the next funding round even closes. There’s no slack built into that kind of timeline.
AI-assisted testing works because it actually matches that rhythm. Feed it a product requirement doc, let it generate test cases overnight, and a developer walks in the next morning to a short list of what broke instead of a blank screen and a guessing game.
That’s not a small thing. It’s hours back every week, and on a runway that’s already tight, hours turn into money pretty fast.
When AI writes the code, too
A growing share of the code shipping into these apps was written by an AI assistant in the first place, and that code tends to pass the obvious checks while failing quietly at the edges.
A field comes back empty instead of null. A request arrives out of order. These are exactly the spots scripted automation never thought to test for, because nobody wrote a test for a bug nobody predicted yet.
This is where AI testing tools earn a second job beyond speed. Several platforms now generate boundary and edge case tests aimed specifically at the failure patterns common in AI-written code, instead of just mirroring whatever a human QA engineer would have scripted by hand for an older kind of codebase.
It does not catch everything, and it should not be trusted to. It catches more of this particular category than a manual checklist built for a different era of code ever could.
Nightly regression without adding headcount
Most teams cannot hire their way out of a growing regression suite… not in a market where a senior QA engineer in the Bay Area can cost more than the feature they are testing took to build.
AI-driven test selection cuts out that waste. It checks what actually changed in a build and only runs the tests that touch that code, so a typo fix on a settings screen doesn’t drag the entire suite through the pipeline.
The full suite still runs on a schedule, usually overnight, so nothing slips through permanently. What changes is the daily rhythm. A developer pushes a change at five, the relevant subset of tests runs while everyone is asleep, and the flagged failures are sitting there by the time anyone is back at a desk. Nobody had to stay late to make that happen.
What The Numbers Actually Show
None of this is evenly distributed yet, and it is worth being honest about that before assuming every QA team has already made the jump. The table below lays out the rough difference between manual testing, scripted automation without AI, and AI augmented testing as it actually runs in practice right now.
| Approach | Typical regression cycle for a mid-sized app | Maintenance load after a UI change | Share of QA teams using it in some form, 2026 |
| Manual testing only | 3 to 5 days | High, every script is reviewed by hand | Declining as the default for funded startups |
| Scripted automation, no AI | 4 to 8 hours | Moderate, locators break with most redesigns | Still common, but no longer the default choice |
| AI augmented testing | Overnight, ready by morning | Low, self-healing tests catch most UI drift | 70 to 72 percent of QA professionals already use AI for some part of testing |
That last row lines up with recent industry surveys, mostly test generation and triage rather than full autonomous testing. That gap between availability and full adoption is worth remembering anytime a vendor claims their tool tests everything end-to-end without anyone watching.
A short list worth keeping before signing off on any AI testing pitch. You should ask:
- What percentage of the test suite still needs a human to review failures before release? Anything claiming zero should worry you, not impress you.
- How the tool handles a UI change it has never seen before, not just one matching its training examples.
- What happens when the tool flags a false positive at two in the morning, and who actually gets paged?
- Which categories of bugs did it catch last quarter that a human reviewer would have missed, with real numbers attached, not a percentage pulled from a slide. Whether the vendor’s own QA team still does manual exploratory testing internally. If they don’t trust the tool enough to skip that step themselves, that tells you something.
The Final Breakdown
None of this changes the actual job of testing software well. It changes who spends time on which part of it. California-based app developers who have made the switch are not testing less carefully.
They are spending less time clicking through screens that have not changed since last week, and more time on the handful of flows that could genuinely embarrass them in front of a user or an investor.
The tools got faster at the repetitive part. The judgment a real person brings to the rest of it did not get replaced, and probably should not be anytime soon.

How to Choose the Right Mobile Testing Tools

What to Look for When Choosing an Office Removal Company

Semen Testing Manchester: A Complete Guide to Male Fertility Testing
Who Is Shameera? All You Need To Know About Charli XCX’s Mother
Meet Rosemary Turner: The Mother of Actor Callum Turner
Who Is Gulliver Flynn Oldman? The Untold Story of Sir Gary Oldman’s Son
-
 Biographies4 months ago
Biographies4 months agoWho Is Shameera? All You Need To Know About Charli XCX’s Mother
-
 Biographies5 months ago
Biographies5 months agoMeet Rosemary Turner: The Mother of Actor Callum Turner
-
 Biographies4 months ago
Biographies4 months agoWho Is Gulliver Flynn Oldman? The Untold Story of Sir Gary Oldman’s Son
-
 Celebrity5 months ago
Celebrity5 months agoWho Is Peter Hernandez? The Real Story of Bruno Mars’ Father
-
 Biographies4 months ago
Biographies4 months agoWho Is Alvin Martin? All About the Whoopi Goldberg’s First Husband
-
 Biographies5 months ago
Biographies5 months agoWho is Todd McRae? Meet Tate McRae’s Father
-

 Biographies3 months ago
Biographies3 months agoWho is Alexandra James? Inside The Life of Jeremy Clarkson’s Former Partner
-
 Biographies4 months ago
Biographies4 months agoWho Is Daniel Mara? The Untold Story of Kate Mara’s Private Sibling